


这篇文档是讲如何利用IFELanguage接口实现对中文语句的分隔,并对词语和字加注拼音的方法。
首先感谢一下Zswang(伴水)兄弟,他的无私奉献精神和对Windows的深入研究值得我们每一个人学习。每次找到好东东他总是给我一份,包括这个IFELanguage接口资料。最初的资料源自一个日本网站,源代码是用VC8写的,Zswang(伴水)将其改写为一个适用于Delphi下的版本。原C++代码经ccrun(老妖)略作修改,在BCB6下调试通过。原VC8的版本和BCB6还有Zswang(伴水)写的Delphi例子代码都一起打包并上传到[常规代码]区,有兴趣的朋友可以下载了研究一下。
首先需要初始化OLE:
#include <ole2.h>
OleInitialize(NULL);
当然,记的在程序结束的时候清场:
CoUninitialize();
我们需一个C++下用的msime.h或Delphi下的msime.pas(感谢Zswang),这个文件里包含了IFELanguage接口,IFECommon接口等声明,还有一些常量和结构的声明,幸亏已经有人替我们做了这部分工作。^_^你只需下载了使用就可以。
#include "msime.h"
// 定义IFELanguage接口的IID
static const IID IID_IFELanguage =
{
0x019f7152, 0xe6db, 0x11d0,
{ 0x83, 0xc3, 0x00, 0xc0, 0x4f, 0xdd, 0xb8, 0x2e }
};
// 指定使用的语言,我们的例子使用简体中文,其他还有:
// MSIME.China
// MSIME.Japan
// MSIME.Taiwan
// MSIME.Taiwan.ImeBbo
LPCWSTR msime = L"MSIME.China";
CLSID clsid;
if(CLSIDFromString(const_cast<LPWSTR>(msime), &clsid) != S_OK)
return;
// 创建一个IFELanguage的COM实例,得到接口指针
IFELanguage *pIFELanguage;
if(CoCreateInstance(clsid, NULL, CLSCTX_SERVER,
IID_IFELanguage, (LPVOID*)&pIFELanguage) != S_OK)
return;
if(!pIFELanguage)
return;
// 打开
if(pIFELanguage->Open() != S_OK)
{
pIFELanguage->Release();
return;
}
//
DWORD dwCaps;
if(pIFELanguage->GetConversionModeCaps(&dwCaps) != S_OK)
// 本文转自 C++Builder研究 - http://www.ccrun.com/article.asp?i=1028&d=r0j832
{
pIFELanguage->Close();
pIFELanguage->Release();
}
// 要解析的中文句子
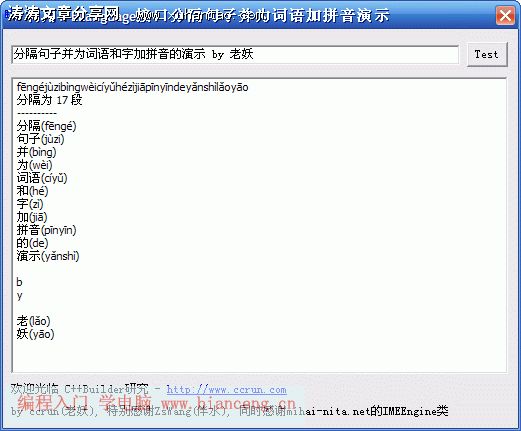
WideString wstrInput = WideString("汉字加拼音演示 妖哥万岁");
MORRSLT *pmorrslt;
// 通过GetJMorphResult方法为汉字加注拼音
if(pIFELanguage->GetJMorphResult(
FELANG_REQ_REV,
FELANG_CMODE_PINYIN |
FELANG_CMODE_NOINVISIBLECHAR,
wstrInput.Length(), wstrInput, NULL, &pmorrslt) != S_OK)
{
pIFELanguage->Close();
pIFELanguage->Release();
}
if(!pmorrslt)
{
pIFELanguage->Close();
pIFELanguage->Release();
}
// 将句子分隔成词语并单独加注拼音
WideString wstrOutput, wstrWord, wstrPinYin;
wstrOutput = WideString(pmorrslt->pwchOutput);
wstrOutput = wstrOutput.SubString(1, pmorrslt->cchOutput);
// pmorrslt->cWDD是分隔后单词的个数(英文单词一个字母算一个)
for(int i = 0; i < pmorrslt->cWDD; i++)
{
// 读取每段的词语或字
wstrWord = wstrInput.SubString(
pmorrslt->pWDD[i].wReadPos + 1,
pmorrslt->pWDD[i].cchRead);
// 读取每段的拼音
wstrPinYin = wstrOutput.SubString(
pmorrslt->pWDD[i].wDispPos + 1,
pmorrslt->pWDD[i].cchDisp);
//
if(wstrPinYin.Length() > 0)
wstrWord = wstrWord + "(" + wstrPinYin + ")";
// 输出结果,我这里仅仅是输出到一个Memo中,在你的应用中记的更改此处,否则编译不过时你又有想法了。
Memo1->Lines->Add(wstrWord);
}
// 记的清场咯
CoTaskMemFree(pmorrslt);
pIFELanguage->Close();
pIFELanguage->Release();
附件中有一个IMEEngine类,原作者可能是个日本程序员。类里仅仅实现了GetJMorphResult的封装,大家可以根据自己的需要自己扩充一下。貌似可以取得汉字的笔画,如果你完成了这部分功能,希望能将代码给我一份: cbfans#163.com,谢谢。
